
Model Inference with Web UI
Once your model is trained, you can deploy it on the AI Worker for inference.
Model Deployment and Inference
1. Transfer Model to Robot PC
INFO
If you trained your model directly on NVIDIA Jetson AGX Orin, you can skip this step.
Change ownership of the model directory. This step must be performed on the robot PC, not inside the Docker container:
sudo chown -R robotis ./Move your model folder from your local PC to the model directory on the Robot PC using scp:
scp -r <your model folder's directory> robotis@<your robot's serial number>.local:~/ai_worker/docker/lerobot/outputs/train2. Open a Terminal and Enter Docker Container
cd ai_worker && ./docker/container.sh enter
3. Launch the ROS 2 Follower Node
WARNING
Please deactivate the ROS 2 teleoperation node launched in the Before You Begin section before proceeding.
ffw_bg2_follower_ai
4. Run Inference
a. Launch Physical AI Server
WARNING
If the Physical AI Server is already running, you can skip this step.
Open a new terminal and enter the Docker container:
cd ai_worker && ./docker/container.sh enter
Then, launch the Physical AI Server with the following command:
ai_serverb. Open the Web UI
Open your web browser and navigate the Web UI (Physical AI Manager).
(Refer to the Dataset Preparation > Web UI > 3. Open the Web UI)
On the Home page, select the type of robot you are using.
c. Enter Task Instruction and Policy Path
Go to the Inference Page.
Enter Task Instruction and Policy Path in the Task Info Panel, located on the right side of the page.
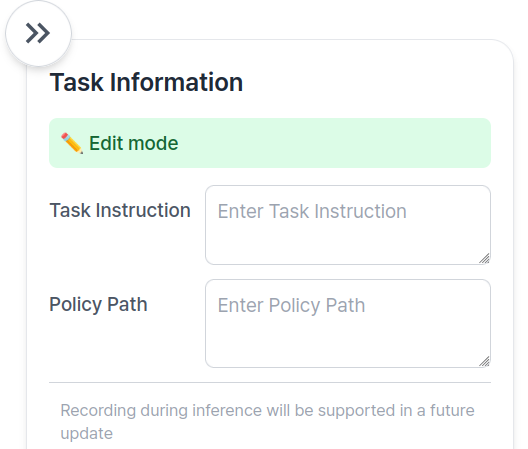
👉 Task Information Field Descriptions
| Item | Description |
|---|---|
| Task Instruction | A sentence that tells the robot what action to perform, such as "pick and place object". |
| Policy Path | The absolute path to your trained model checkpoint directory. This should point to the folder containing your trained model files such as config.json, model.safetensors, and train_config.json. (e.g., /root/trained_model/ffw_act/pretrained/). |
INFO
Recording during inference will be supported in a future update. Coming soon!
d. Start Inference
To begin inference, use the Control Panel located at the bottom of the page:

- The
Startbutton begins inference. - The
Finishbutton stops inference.
Visualizing Inference Results
After running inference, you can visualize the results using the same visualization tool used for datasets:
python lerobot/scripts/visualize_dataset_html.py \
--host 0.0.0.0 \
--port 9091 \
--repo-id ${HF_USER}/eval_ffw_testThen open http://127.0.0.1:9091 in your browser to see how your model performed.
TIP
If you have another device connected to the same network as the host machine, open http://{robot type}-{serial number}.local:9091 in your browser to see how your model performed.
For example, http://ffw-SNPR48A0000.local:9091.
Troubleshooting
- Out of memory errors: Try reducing the batch size with
--train.batch_size=16or lower - Low performance: Consider collecting more diverse training data or increasing training duration
- Robot not responding: Ensure the follower node is running and communication is established
- Training divergence: Check your dataset quality and try decreasing the learning rate